列存儲格式ORC與Parquet詳解及其在數據處理和存儲服務中的應用比較
引言:列存儲時代的崛起
隨著大數據技術的飛速發展,傳統行式存儲(如CSV、JSON)在處理海量數據分析任務時,逐漸暴露出I/O效率低、壓縮比差、查詢性能瓶頸等問題。在此背景下,列式存儲格式應運而生,通過將同一列的數據連續存儲,極大地優化了讀取性能、壓縮效率和查詢速度。Apache ORC(Optimized Row Columnar)和Apache Parquet作為當今最主流的兩種列式存儲格式,已成為構建現代數據湖、數據倉庫及數據處理管道的事實標準。本文將對ORC和Parquet進行深入解析,并從數據處理和存儲支持服務的角度,系統比較兩者的特性與適用場景。
核心特性解析:ORC與Parquet的技術架構
1. Apache ORC
ORC最初由Hortonworks為優化Hive性能而設計,現已發展為Apache頂級項目。其核心設計思想是“為讀寫Hive數據而優化”。
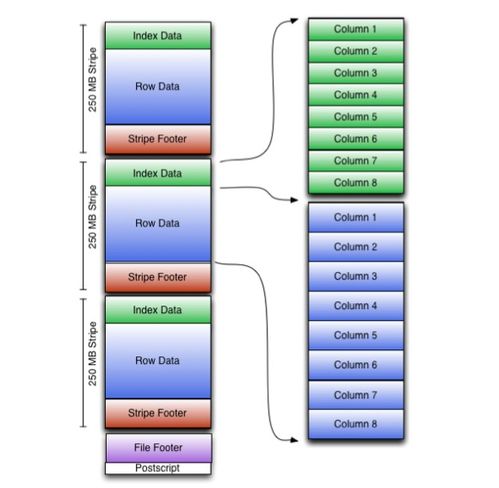
- 文件結構:ORC文件由 stripes(條帶)、file footer(文件尾部)和 postscript(后記)組成。每個stripe通常包含多行數據(默認為10,000行),內部又細分為Index Data、Row Data和Stripe Footer,其中索引數據支持實現高效的謂詞下推和跳過無關數據塊。
- 類型系統:緊密集成Hive數據類型,對復雜類型(如struct、list、map)支持良好。
- 編碼與壓縮:采用多種輕量級編碼(如Run-Length Encoding、Dictionary Encoding)結合zlib、Snappy、ZSTD等壓縮算法,通常能達到極高的壓縮比。
- ACID支持:ORC原生支持Hive事務(ACID),允許在表級別進行更新、刪除和合并操作,這對于需要處理緩慢變化維度或實時更新的場景至關重要。
- 謂詞下推:通過內置的布隆過濾器和索引,可在讀取時高效過濾數據,減少I/O。
2. Apache Parquet
Parquet由Twitter和Cloudera聯合創建,靈感來自Google的Dremel論文,強調跨生態系統的兼容性和高性能。
- 文件結構:采用分層結構,由Row Group、Column Chunk和Page構成。Row Group是數據水平分割的邏輯單元,Column Chunk代表一個列在Row Group內的數據,Page是壓縮和編碼的最小單位。這種結構便于并行處理。
- 類型系統:基于Dremel的嵌套數據模型,對嵌套數據結構(如JSON、Protocol Buffers、Avro)的支持尤為出色,無需扁平化即可高效存儲。
- 編碼與壓縮:支持靈活的編碼方式(如Dictionary、Plain、Delta Encoding),并常用Snappy、GZIP壓縮,在保持良好壓縮比的注重讀寫速度的平衡。
- 架構無關性:設計目標是與數據處理框架(如Spark、Presto、Impala)和查詢引擎解耦,擁有廣泛的語言綁定和生態系統支持。
- 豐富的元數據:在文件尾部存儲詳細的統計信息(如最小值、最大值、空值計數),優化查詢計劃。
數據處理與存儲支持服務角度的深度比較
| 比較維度 | ORC | Parquet | 對數據處理與存儲服務的啟示 |
|----------------------|----------------------------------------------|----------------------------------------------|------------------------------------------------------------|
| 生態系統與集成 | 深度集成Hadoop/Hive生態,是Hive默認存儲格式。與Spark、Presto等集成良好,但在非Hive場景下,工具鏈相對專一。 | 生態系統極為廣泛,是Spark默認推薦格式,與Impala、Presto、Arrow、AWS Athena/Glue等云服務深度集成,跨平臺性極佳。 | Parquet在構建多引擎、多云環境的現代數據平臺時更具靈活性。ORC在傳統Hive數倉中仍是可靠選擇。 |
| 讀寫性能 | 寫性能通常更優,因其結構針對Hive MR作業優化。讀性能在基于Hive的查詢中表現卓越,特別是全表掃描和聚合查詢。 | 讀性能在多數分析型查詢中領先,尤其是涉及嵌套列和選擇性投影時。Spark等引擎對其優化極深。寫開銷可能略高于ORC。 | ETL管道寫入密集型且基于Hive:考慮ORC。交互式分析、多維度查詢為主:Parquet往往更快。 |
| 存儲效率與壓縮 | 通常能達到更高的壓縮比(尤其在文本數據上),節省存儲成本。 | 壓縮比優秀,與ORC互有勝負,更側重于平衡壓縮率與解壓速度。 | 對存儲成本極度敏感(如冷數據歸檔),ORC可能有優勢。對需要快速掃描的熱數據,Parquet的平衡性更佳。 |
| 模式演進與兼容性 | 支持模式演進(如添加列),但ACID事務的支持使其在更新場景更獨特。 | 對模式演進的支持非常成熟和優雅,被廣泛用于數據湖場景,適應數據模式隨時間變化的常態。 | 數據湖架構、模式變化頻繁:Parquet是首選。需要行級更新的事務表:ORC的ACID支持不可替代。 |
| 嵌套數據支持 | 支持,但設計和優化更多圍繞Hive的SQL-on-Hadoop場景。 | 原生為嵌套數據設計,存儲和查詢效率更高,是處理半結構化數據(如JSON)的理想選擇。 | 數據源多為JSON、Avro或具有復雜嵌套結構:強烈推薦Parquet。 |
| 云原生與對象存儲 | 兼容主流對象存儲(S3、ADLS、GCS),但文件不可分割性在某些場景下可能影響性能。 | 同樣兼容良好,且由于其元數據結構和廣泛優化,在云上交互式查詢服務(如Athena、BigQuery)中通常是第一公民。 | 云上數據湖建設,Parquet的社區支持和云廠商優化通常更全面。 |
與選型建議
ORC和Parquet都是卓越的列式存儲格式,沒有絕對的優劣,只有更適合的場景。
- 選擇Apache ORC,當您的場景是:
- 以Hive為中心的傳統數據倉庫,且工作負載大量涉及Hive SQL。
- 對存儲空間壓縮比有極致要求,存儲成本是首要考量。
- 業務需要Hive表級別的ACID事務支持,進行頻繁的行級更新、刪除。
- 選擇Apache Parquet,當您的場景是:
- 構建以Spark、Presto、Impala等現代引擎為核心的數據湖或數據平臺。
- 數據源或模型包含大量嵌套、半結構化數據。
- 追求最廣泛的生態系統兼容性,需要無縫對接多種計算引擎和云服務。
- 業務以復雜的交互式分析查詢為主,且模式可能隨時間演進。
未來趨勢與融合:隨著數據處理服務的發展(如Delta Lake、Apache Iceberg、Hudi等表格式的興起),ORC和Parquet更多作為底層物理存儲格式被封裝。這些高級表格式在提供ACID、時間旅行等功能的讓用戶無需在ORC和Parquet之間做出艱難抉擇,有時甚至支持兩者作為底層文件格式。因此,在架構選型時,也應將上層表格式的生態支持納入考量。
一個混合并存的環境也可能是合理的——在同一個數據平臺中,根據數據的特點、訪問模式和生命周期管理策略,為不同的數據集選擇最合適的存儲格式,方能最大化數據處理與存儲服務的效能與成本效益。
如若轉載,請注明出處:http://www.hashiqiquan.cn/product/67.html
更新時間:2026-06-03 10:03:48